Decouple then integrate
A two-stage autoregressive ControlNet-based framework — learn human-motion control under static cameras, then progressively introduce camera-trajectory control on top of the acquired motion prior.
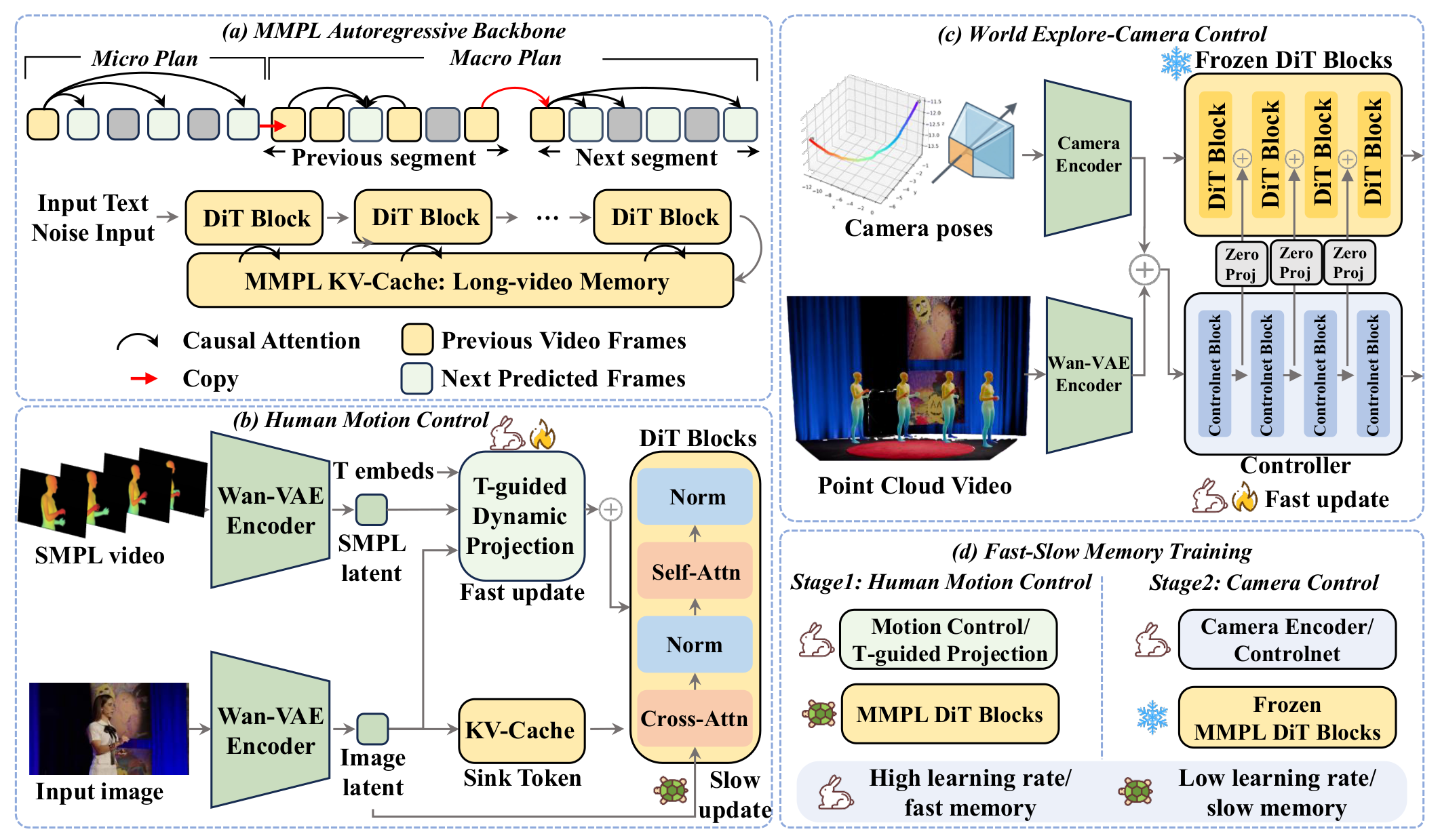
Figure 1. Controllable autoregressive framework: MMPL backbone · SMPL human-motion control with t-guided projection · causal-aligned camera control · Fast–Slow Memory training.
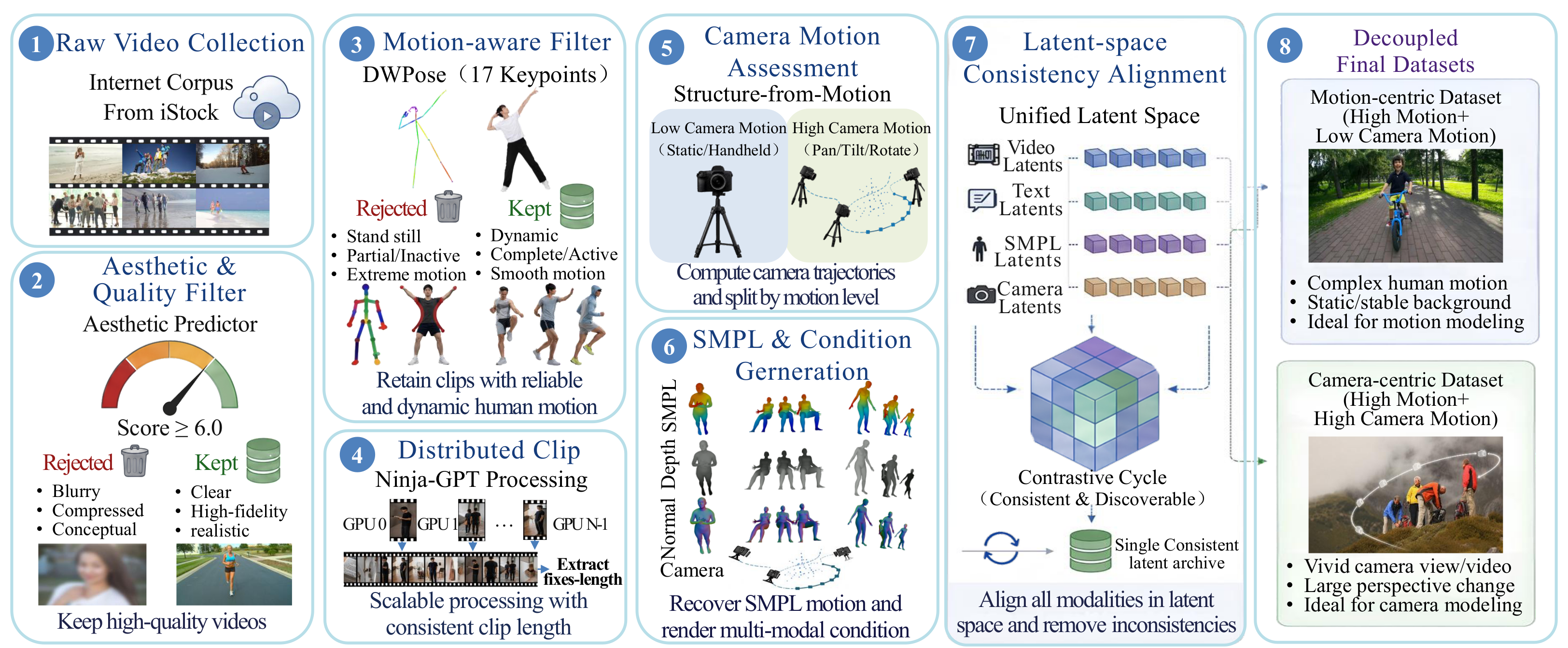
Figure 2. Dataset construction: 20M iStock videos → aesthetic & motion filtering → distributed condition extraction (normal/depth/SMPL) → SfM camera assessment → unified-latent-space alignment → decoupled motion-centric & camera-centric subsets.
01 MMPL Backbone
A Plan-then-Populate autoregressive backbone that predicts sparse planning frames (including the terminal anchor) to constrain each block, connecting consecutive segments into temporally consistent long videos with stable world memory.
02 Human Motion Control
SMPL sequences injected as structured 3D guidance via a t-guided Dynamic Projection that adapts motion conditions to timestep-dependent denoising latents — coarse-to-fine control that also supports simultaneous multi-person motion.
03 Causal-Aligned Camera Control
A camera pathway that decouples global Plücker-ray trajectory encoding from block-local feature injection — preserving long-range trajectory understanding while staying temporally aligned with block-wise autoregressive generation.
04 Fast–Slow Memory Training
A differential learning-rate strategy: self/cross-attention layers stay slow to preserve the long-video prior, while new control modules adapt fast — stabilizing controllable post-training and reducing signal interference.